GitHub API Flow 介紹以及實作
身為前軟體工程師,雖然當了運維工程師,但還是會需要碰到 GitHub 以及開發工作,最近遇到一個情況是要使用 GitHub API 去實作出一套 CMS 系統,讓內部開發者可以透過介面自動提交對應的檔案,申請 AWS 資源。
本篇會介紹實作自動化 GitHub Flow 時候,看到 API 規格時仍舊一頭霧水,原本以為自己已經很熟 Git 了,真正要實作時才發現對其運作的原理還有很大的進步空間,所以查了很多資料整理出來這篇筆記。文章會介紹直接對 GitHub repo 操作的流程,就不用再把整包程式碼 clone 到本地端了。
環境以及使用版本
- GitHub REST API Version:
- GitHub Enterprise Server 3.5
- Free, Pro, & Team
為什麼選擇 GitHub Flow
通常想到 GitHub 的 CICD,第一直覺會想到用 GitHub Actions 來實作,但是 GitHub Actions 還是要透過提交 PR 來觸發,假設你遇到的情況是使用者完全不清楚他要提交什麼內容的時候,就會需要連同 PR 觸發也一起搞定的流程。
GitHub Flow 有很多種,如果想要了解的話可以參考 Git上的三種工作流程,已經有人整理好可以對照來看,在我的應用場景會需要使用到的是把 Upstream - Forked Repo - Local 的這種作法,詳見下圖示意:
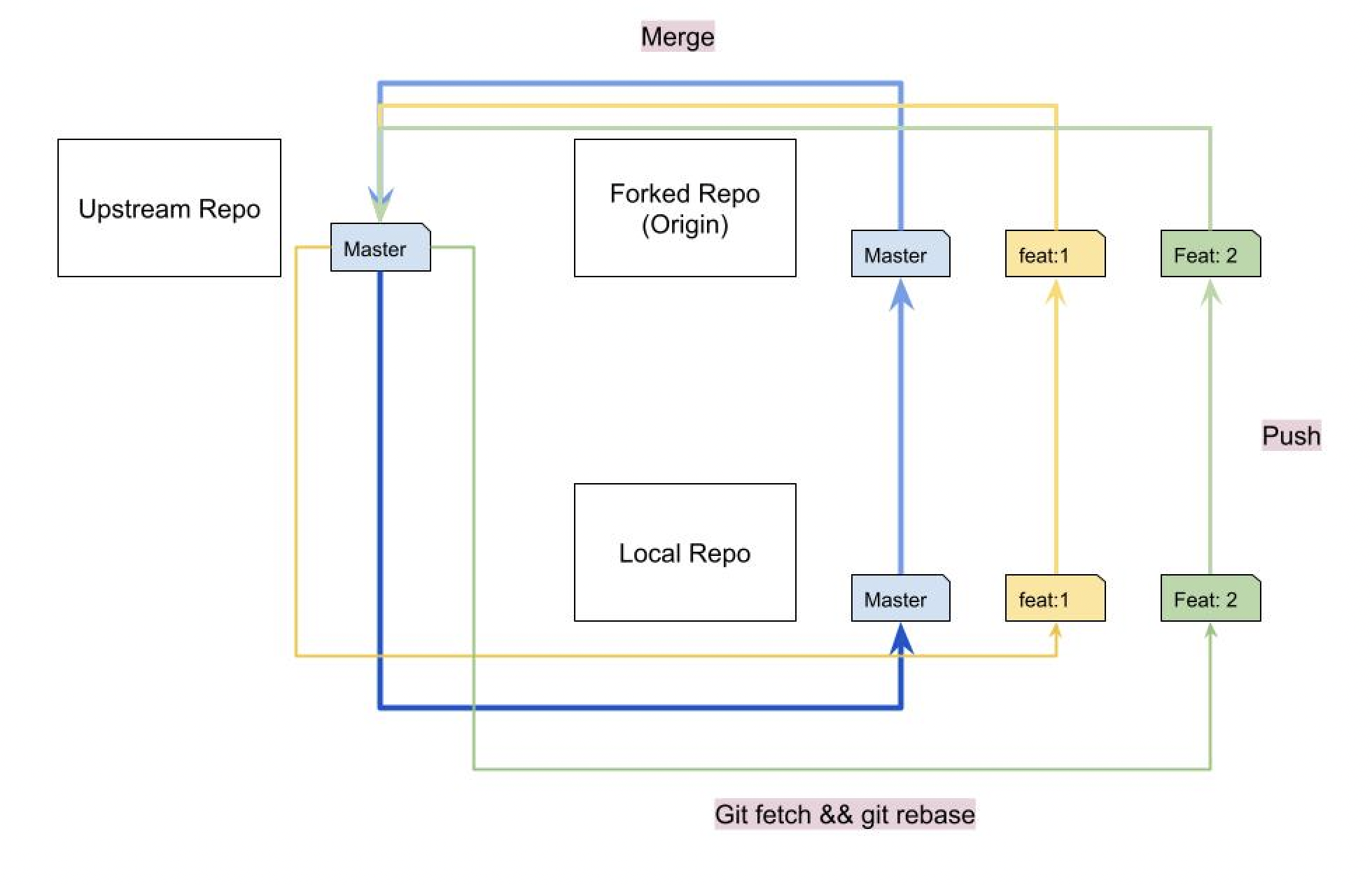
這種作法會直接把 upstream repo 的 master(main) 分支拉到 local repo 的 feature branch,開發後推送到 fork repo 的對應分支進行測試環境的 CI 工作,也就是觸發各種 GitHub Actions/CI triggers,最後合併進 upstream 的 master(main) 分支,往復循環。
這種作法的優點有兩個:
- 分支都開在自己
fork的repo上,比較不會跟別人的分支名稱混在一起 - 假設自己做的功能需要客製化的
CI測試,可以用GitHub Actions做在自己的 Repo 上面,這樣Upstream就只要進行綜合性的整合測試即可。
對應 GitHub Flow 的 GitHub API 簡單介紹
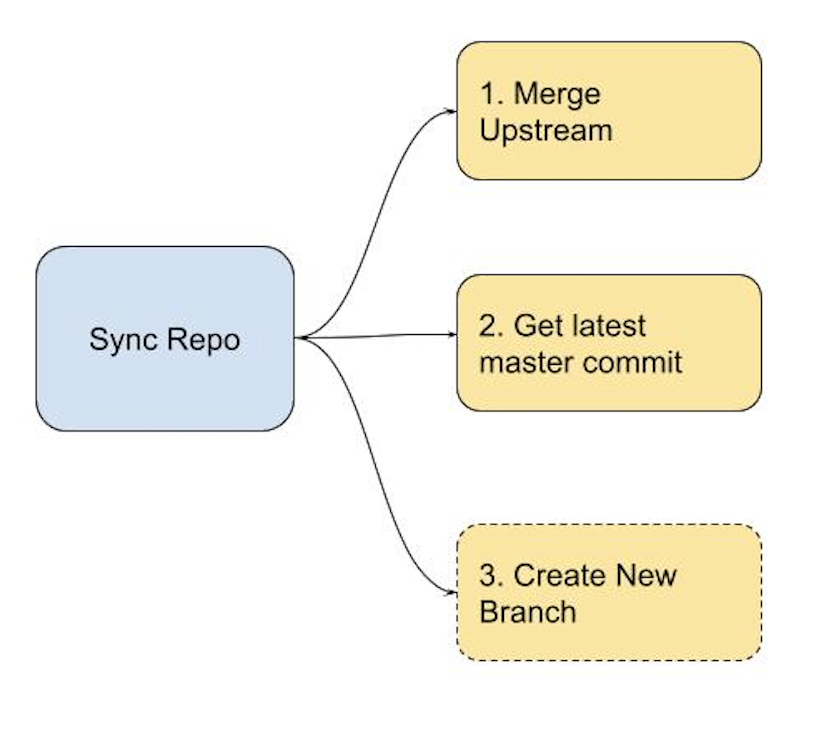
從上面的示意圖可以看出如果要完成一次 PR 提交,主要有三個步驟:
- 從 upstream 拉程式碼到分支: git fetch upstream/master && git rebase upstream/master
- commit 並且推送到 fork repo: git add && git commiit && git push
- 向 upstream 的 master 開 PR
如果是指令的操作,相信各位都蠻熟悉的。但假設我們今天是要在一台自動化的跳板機上面做這件事情,我不會想要花時間把整包 repo fork 下來,所以現在需要透過 GitHub API 直接對我們 fork 的 repo 進行操作。把上面的三個步驟對應到 GitHub API,就會像下面這幾張圖,每張圖下面我會稍微講解一下這個步驟在做什麼,以及需要記下的資訊:
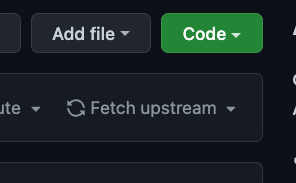
- 會使用到 Merge Upstream ,這個
API會幫你把Upstream的 master fetch and rebase 到fork repo的master分支,相當於這個按鈕的功能:
- 使用到的是 refs,這支
API會幫你把某個分支的最新的commit給抓出來,在這邊因為我需要從master分支開出新分支,所以實作的範例如下:
1 | def get_latest_commit(host_name, repo_name, git_token): |
這邊的 latest_commit 實作時可以存在變數裡,創建 commit 會需要用到
- 最後會需要開新的分支,使用到的是 Create a reference,這邊可能會有人覺得 API 的命名很奇特(例如我),為什麼會使用
reference呢?基本上你可以視reference為branch,它就像是一個標籤,你可以更新它的head到某個commit,以下是實作的範例:
1 | def create_new_branch(host_name, repo_name, git_token, branch_name, latest_commit): |
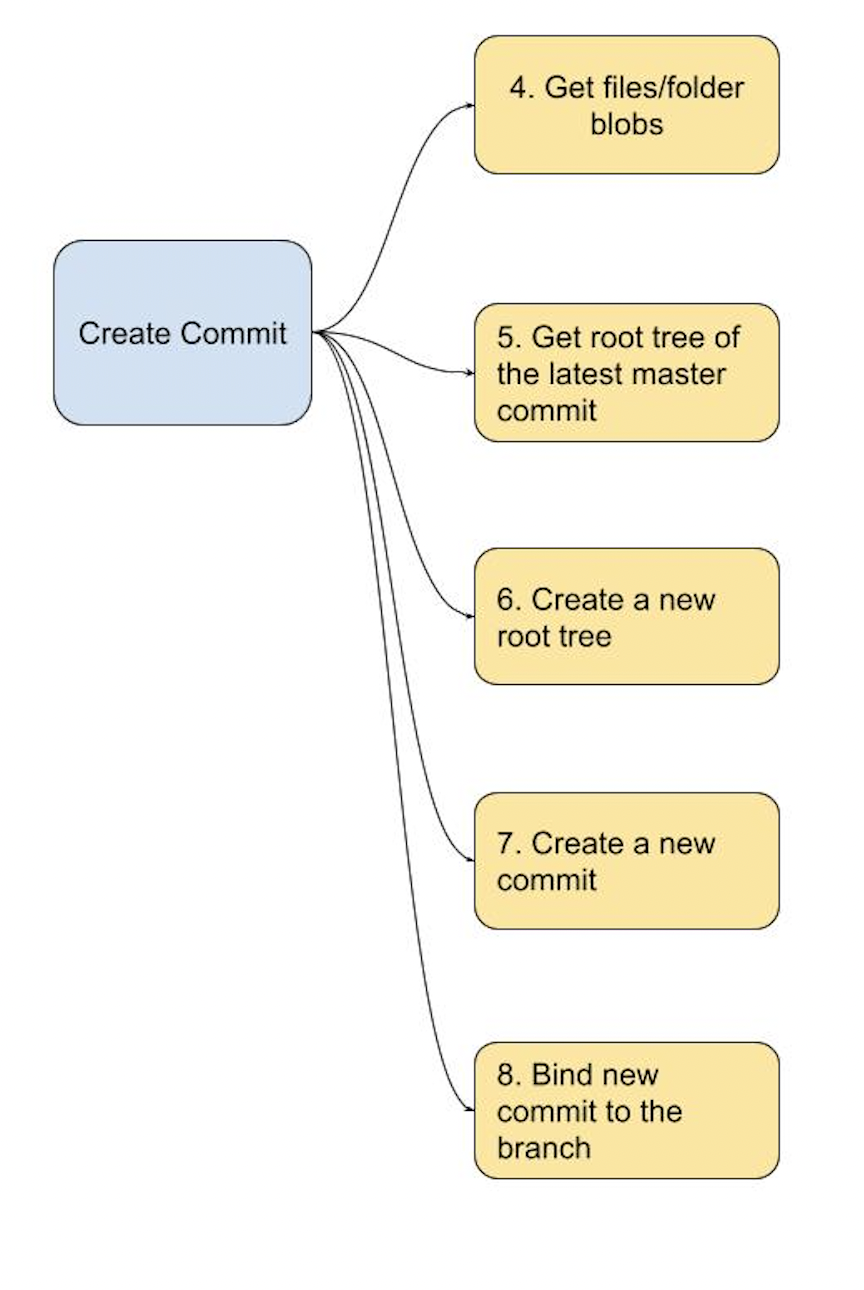
接下來會需要執行第二區塊,把新增的檔案加入一個提交 commit,這邊會需要幫所有檔案創建出 blob 物件,並且拿到 GitHub Database 的 SHA256 code, GitHub Database 的 API 的使用方法以及圖解可以參考 Getting started with the Git Database API,裡面有講解 commit, tree 和 file 的關係。
每次我們使用 git add 指令加入檔案的時候,都會生成一個 blob 物件儲存在本地端的 git,然後在提交 commit 的時候,會把這些 blob 物件的 SHA256 key 集合起來,生成一個 tree (有點像是演算法的子樹的概念),最後推送到遠端的分支時,會更新遠端分支最新 commit 的整個 root tree,並且生成新的 root tree。
第四步開始,我們需要把所有想提交的檔案都呼叫遠端的 API 拿到 blob 的 SHA256 key。原本使用指令的方式可以直接在本地的 git database 生成,但這次的目標是本地不要有任何 Git Repo,只保留呼叫 API 的邏輯,所以有多少檔案就要呼叫多少次 API,因為 GitHub 在檔案上傳這塊沒有提供一次上傳多個或是上傳一個資料夾的 API。
這步驟使用的 API 是 Create a blob,這邊需要注意的點有兩個:
- 上傳前需要寫個把檔案
encode成uft-8或是base64的邏輯 (GitHub API 的規格),再把產出物填到呼叫的payload裡 - 檔案的路徑和之後你要拿的
root tree從哪邊開始有關,我這邊是直接填寫repo根目錄到這個檔案的整條filepath
這邊直接展示範例程式碼比較清楚:
1 | class Blob: |
第五步驟是要拿到現在這個分支最新 commit 的 tree,呼叫 get tree API 之後會吐回來這個tree 的 SHA256 key,這邊一樣實作時先存在變數裡,後續會需要用到。以下是範例程式碼,因為看 GitHub 文件的範例可能會有點疑惑,我這邊是直接拿 fork repo 的 master 分支的 tree,開出來的分支一樣是指到 master branch 的最新 commit,只要 commit 一致,tree 的 SHA256 key 就會一樣:
1 | def get_master_branch_tree(host_name, repo_name, git_token): |
第六步驟是要更新第五步驟拿到的整棵 root tree,這邊我是拿整個 repo 的 root tree,而不是更新某顆 sub tree (就是其中的某個資料夾的意思),如果有特定的 sub tree 需要更新的話,從第四步驟上傳 blob 開始,就要注意填寫上傳檔案的相對路徑,不然會導致更新到錯誤的資料夾,甚至把資料刪掉這種慘事。有錯誤的話,在開 PR 的時候都會看到,所以不需要太擔心。
這個步驟算是比較難懂一點,而且跟你上傳檔案時填寫的路徑有關,所以我這邊畫了一張示意圖,會比較好懂點:
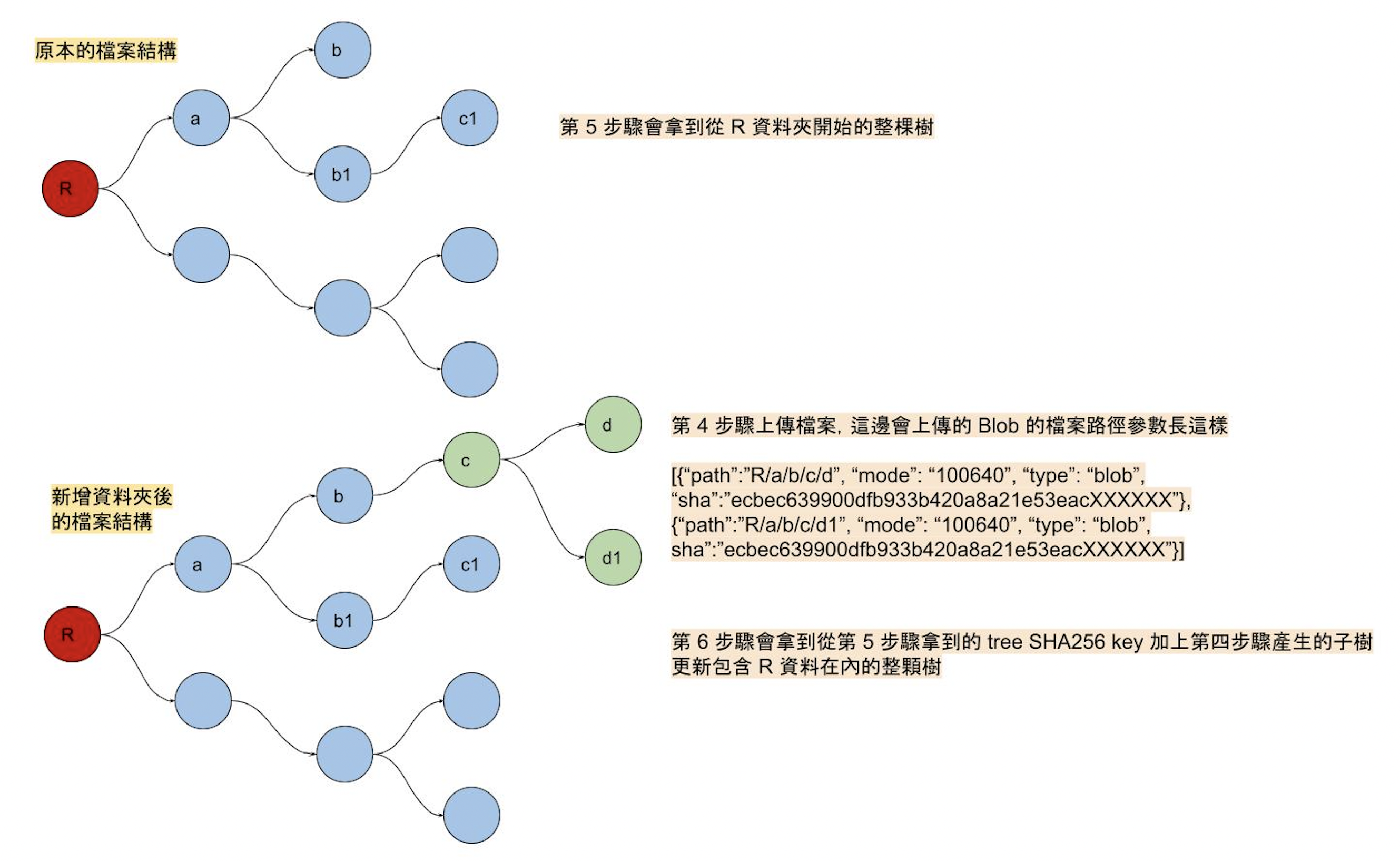
這個步驟會用到 Create a tree,範例如下:
1 | def create_new_tree_by_folder(host_name, repo_name, git_token, base_tree): |
第七步驟,透過 Create a commit API 提交 commit,這邊回傳的 commit SHA256 記下來,下步驟會用到,範例如下:
1 | def create_new_commit(host_name, repo_name, git_token, latest_master_commit, new_tree_sha): |
第八步驟,透過 Update a reference API 把新建的 branch (reference) 指到剛剛提交的 commit,這樣才算是完整更新 branch,範例如下:
1 | def bind_commit_to_branch(host_name, repo_name, git_token, new_branch, new_commit_sha): |
到這邊已經克服了最難的魔王了。第九步驟超簡單的,就是呼叫 開 PR 的 API,對 upstream 提交分支合併的請求。
結語
這樣的工作流程算是步驟蠻多的,而且參數的傳遞需要稍微整理一下才不會搞混,但是還是有兩大優點:
第一是不需要花額外的儲存空間去存
clone下來的Repo,這樣的特性讓這個自動化程式可以運行在各種Infrastructure架構,比方說Kubernetes上,因為開發者是用自己的repo在提交PR,所以不會存在分支名稱衝突,就算檔案有衝突,也會在開PR的時候看到衝突結果。第二是統一幫開發者開
PR,因為不能確保每個開發者提交PR的習慣都照著fetch & rebase的流程來,而且有些開發者會提交很多次的commits,這樣PR不夠簡潔,這個流程可以確保檔案的新增都在一個PR內。
或許有些用過 GitHub API 的人會提出為什麼不使用 Create or update file contents API 針對要新增的檔案做循序新增?
因為這個 API 做的事情是拿到 blob sha + 直接把檔案 commit,假設要提交的檔案很多,最後開出來的 PR 一樣會有很多 commits 紀錄,這樣 PR 會很醜,身為工程師還是要有美感。
老實說我在第二步驟的 tree 的更新這邊卡超久,大概試了三個小時才終於開出正確的 PR,而且因為步驟太多,所以中間一度要靠著不斷嘗試才知道錯誤出在哪個步驟。不過理清了順序和原理之後,這套流程就可以改成任何想要的自動化提交 PR 內部系統的功能,也算是花時間徹底了解整個 GitHub Flow 的原理和複習下 GitHub Database。
Reference
🍀 Git上的三種工作流程
🍀 GitHub API - Create or update file contents
🍀 GitHub API - Sync a fork branch with the upstream repository
🍀 GitHub API - Get a reference
🍀 GitHub API - Create a reference
🍀 GitHub Docs - Getting started with the Git Database API
🍀 GitHub API - Create a pull request
🍀 GitHub API - Create a blob
🍀 GitHub API - Get a tree
🍀 GitHub API - Create a tree
🍀 GitHub API - Create a commit
🍀 GitHub API - Update a reference
🍀 GitHub API - Create or update file contents
🍀 Create a folder and push multiple files under a single commit through GitHub API
🍀 StackOverflow - How to create a commit and push into repo with GitHub API v3?