從 GCP 到 AWS:如何為掃地機器人雲端服務設計一個零停機跨雲遷移策略
🔹 前言
真實環境往往不是「最佳實踐」,而是在崎嶇的路途中找到通往目的地的路。
這篇文章記錄的是:
- ❌ 不是「很熟 GCP,所以很順利」
- ❌ 不是「有完整的測試環境」
- ❌ 不是「順利的搬遷可以立刻看到結果」
而是:
- ✅ 沒用過 GCP
- ✅ 用戶是全球數百萬台掃地機器人(你無法控制它們的 DNS cache)
- ✅ 搬的是雲端更新系統(出錯就完蛋)
- ✅ 零停機
如果你期待看到「完美的教科書案例」,這篇不適合你。
但如果你想知道 在有限的條件下,怎麼完成零停機遷移任務,Let’s go。
⚠️ 免責聲明 (Disclaimer):
本文基於真實專案經驗撰寫,為符合保密條款,部分產業、公司與數據細節已匿名化。
技術內容與挑戰皆為真實案例,僅代表作者個人經驗,不代表任何企業立場。
This article is based on real-world project experience. Some industry and company details have been anonymized to comply with confidentiality obligations. The technical content and challenges described reflect the author’s personal experience only.
🔹 背景:Welcome to your MISSION
任務
- 目標: GCP 到 AWS 雲端服務遷移
- 系統類型: 掃地機器人的韌體更新系統
- 用戶特性:
- 用戶是「裝置」而非「人」
- 每天更新一次
- 數量:大規模(數百萬等級)
- 要求: 零停機
團隊
- 後端工程師 和 SRE 🌸
🔹 四大挑戰
| 挑戰項目 | 理想中的遷移情境 | 真實的 IoT 遷移挑戰 | 對營運的實質影響 |
|---|---|---|---|
| 反應遲緩的反饋機制 | DNS 切換後能立刻從監控圖表看到流量位移,出問題時能在一分鐘內發現並啟動回滾。 | 裝置(如掃地機器人)具有固定的查核週期,且全球各地的 ISP 與韌體快取行為各異。 | 流量轉移呈現長尾效應,可能在切換 24 小時後才發現局部災難。 |
| 系統容錯率極低 | 一般 Web 應用更新失敗時,影響多半侷限於服務可用性,修復後重新部署即可恢復。 | 遷移標的是支撐數百萬台設備的「韌體更新系統」,是裝置穩定運作的生命線。 | 任何環節失誤都可能導致裝置更新失敗甚至失效,直接衝擊企業聲譽,並帶來巨大的營運與客服壓力。 |
| 跨雲平台的技術落差 | 團隊對目標雲端平台的架構、API 與各類服務的最佳實踐已有深厚經驗。 | 團隊需在高度時間壓力下,同時學習並理解 GCP 的 DNS 行為與負載均衡日誌結構。 | 在高壓環境中快速平移技術能力,必須極其謹慎地完成架構對齊,否則容易引入隱性故障或安全缺陷。 |
| 測試環境的先天缺陷 | 擁有與生產環境完全一致的 Staging 環境,可反覆演練端對端的流量切換。 | Staging 無法真實模擬全球數百萬台裝置分佈於不同 ISP 與地區下的 DNS 快取行為。 | 測試結果與真實環境存在物理隔閡,迫使系統必須在生產環境中具備極致的觀測能力與高精準度回滾機制。 |
我們必須「第一次就做對」,因為:
- 沒有即時反饋:要等一天才知道對錯
- 沒有 staging 緩衝:出錯直接影響所有掃地機器人
- 沒有經驗可循、技術理解有落差
- 系統重要性:韌體更新出錯補救難度高
🔹 第一個月:看文件從零開始學
任務:搞懂 GCP Cloud DNS 以及 GCP Load Balancing Logging 怎麼查
學習 vs 現實的落差
| 📚 文件教我的 | 💀 實戰需要的 | 結果 |
|---|---|---|
| Record set 結構 | Production DNS 切換的坑 | ❌ 沒教 |
| TTL 設定方式 | 延遲反饋系統的驗證法 | ❌ 沒教 |
| Propagation 行為 | 出問題時的 rollback 步驟 | ❌ 沒教 |
| 基礎操作 ✅ | 零停機遷移 ❌ | 只能實戰中學 |
問題:
- 官方文件:給「有 staging」的人用的
- YouTube:教「怎麼建 DNS record」不是「怎麼安全遷移」
- Google:找不到「無 staging + 延遲反饋」的案例
學到什麼:
1 | 理論知識 ✅ 有了 |
🤔 我當時沒想到的問題(後來才知道很重要)
| 類別 | 問題 | 實際答案 |
|---|---|---|
| DNS 層 | GCP 跟 AWS DNS API 差異? | 語法不同,但概念相同 |
| 不同地區 propagation 時間差多少? | 理論 5 分鐘,實際可能幾小時 | |
| 百萬裝置同時查詢會塞車嗎? | DNS 本身沒問題,但機器人的 cache 行為無法預測 | |
| 掃地機器人行為 | DNS cache 行為是什麼? | ⚠️ 無法控制(不同韌體版本行為不同) |
| 更新途中斷線會重試嗎? | 會,但間隔時間不確定 | |
| 不同韌體版本行為一樣嗎? | ❌ 不一樣,這是最大的坑 | |
| 驗證方式 | 怎麼知道「所有」機器人都切換成功? | 只能靠 GCP 流量監控(從百萬降到零) |
| 1% 機器人卡住會發現嗎? | ⚠️ 不一定,除非主動查流量 |
為什麼當時沒想到?
1 | 1. 從來沒做過這種規模的遷移 |
⏰ 時間壓力下的學習策略
時間分配:
| 時間 | 做什麼 | 目的 | 產出 |
|---|---|---|---|
| 2 天 | 快速看官方文件 | 抓重點,建立基礎認知 | 理解雲供應商 DNS 基本概念 |
| 1 天 | YouTube 操作示範 | 建立操作直覺 | 知道介面長什麼樣 |
| 3 天 | dev 環境實際操作 | 踩坑(最重要) | 發現文件沒說的問題 |
| 2 天 | 寫筆記 + 整理「不知道清單」 | 風險管理 | 產出風險應對表單 |
學習目標:不是「學完」
| ✅ 要達成的 | ❌ 不用追求的 |
|---|---|
| 知道基礎操作怎麼做 | 成為 GCP 專家 |
| 知道自己「不知道什麼」 | 理解所有細節 |
知道哪些要在 dev 先測試 |
保證不會出問題 |
「不知道清單」→ 風險應對表(後來救了我們):
| 風險問題 | 應對方案 | 驗證方式 | 時間目標 |
|---|---|---|---|
| DNS 切換的最壞情況是什麼? | 準備完整 rollback 步驟文件 | dev 環境測試 rollback | < 5 分鐘完成切回 |
| Rollback 要多久? | 寫成 SOP,測試 3 次 | 計時每次執行時間 | 確保 < 5 分鐘 |
| 怎麼驗證「真的」切換成功? | 手動檢查樣本 + 流量監控 | 抽查 IP 地理位置,GCP console 有地理流量表 | 上線後立即執行 |
| 如果有機器人卡住怎麼辦? | 非同步抄寫維持一個月 | 監控 GCP 流量趨勢 | 等流量降到趨近零 |
| 如果出現未知錯誤怎麼辦? | 保持 GCP 同步運作 | 兩邊系統都能接流量 | 隨時可切回 |
這份清單的價值對比:
| 沒有清單的做法 | 有清單的做法 |
|---|---|
| 😰 「希望不要出問題」 | 😤 「出問題時知道怎麼辦」 |
| 😰 遇到問題才開始想怎麼辦 | ✅ 每個風險都有預案 |
| 😰 慌張中做決定(容易錯) | ✅ 照著清單執行(不慌) |
| 😰 不知道準備夠不夠 | ✅ 知道自己準備了什麼 |
清單不能保證覆蓋所有會出錯的邊緣案例,但至少心裡踏實些。
🔹 第二個月:開發環境測試
測試環境說明
| 項目 | Dev 環境 | Production 環境 | 差異影響 |
|---|---|---|---|
| 流量規模 | 模擬少量請求 | 日流量千萬次請求 | ⚠️ 無法真實驗證效能 |
| 設備數量 | 幾台測試機器人 | 百萬級掃地機器人 | ⚠️ DNS propagation 行為不同 |
| 連線分布 | 單一地區 | 全球分布的獨立 IP | ⚠️ 不同地區 DNS cache 行為差異大 |
| 資料庫 | 小型 PostgreSQL | K8s + PostgreSQL(生產規模) | ⚠️ 同步延遲無法驗證 |
| 客戶類型 | 內部測試 | 企業客戶、個體客戶 | ⚠️ 不同韌體版本行為不一致,使用者也不一定會主動更新 |
我們知道的限制:開發環境永遠不等於 Production
🎯 測試重點 1:DNS 切換策略
「不改客戶端域名,只改 DNS 指向。」
現實狀況:
- 掃地機器人分布在全球各地(家庭、企業),多達數百萬台,而且都賣出去很久了
- 韌體部門的開發排程不一定有餘裕臨時接新的請求
- 客戶不一定會升級韌體(懶、忘記、不知道)
- 就算推了新韌體,可能要幾個月甚至半年才全部升級
- 舊韌體的機器人會一直連舊域名
既然韌體改不了、客戶也不會升級,那就只能想辦法「不改韌體、不靠客戶端操作」:
💡 突然想到:「為什麼要一定要換域名?我們自己控制 DNS 啊!」
只要把 GCP Cloud DNS 的 record 指向改成 AWS ALB 的 FQDN,掃地機器人根本不知道後端換了,韌體完全不用動!
graph TB
%% ======== 樣式定義 ========
classDef client fill:#e3f2fd,stroke:#90caf9,stroke-width:2px
classDef dns fill:#fff9c4,stroke:#fbc02d,stroke-width:2px
classDef lb fill:#f3e5f5,stroke:#ba68c8,stroke-width:2px
classDef k8s fill:#e8f5e9,stroke:#66bb6a,stroke-width:2px
classDef db fill:#fce4ec,stroke:#f06292,stroke-width:2px
classDef note fill:#ffccbc,stroke:#ff8a65,stroke-width:2px
ClientNew[大部分機器人
DNS cache 已更新]
ClientOld[少部分機器人
DNS cache 未更新]
DNS[GCP Cloud DNS
robot-update.example.com
TTL: 60s]
subgraph AWS["AWS 環境(主要)"]
LBA[AWS ALB
52.x.x.x]
K8SA[EKS]
DBA[(RDS)]
end
subgraph GCP["GCP 環境(備份)"]
LBG[GCP LB
35.x.x.x]
K8SG[GKE]
DBG[(Cloud SQL)]
end
Note["切換操作:
1. 降低 TTL 至 60 秒
2. AWS 環境完全就緒
3. DNS 指向改為 AWS
4. 監控 GCP 流量衰減
5. 舊 DNS cache 的掃地機器人仍會連到 GCP"]
ClientNew -->|DNS 查詢| DNS
ClientOld -->|DNS 查詢| DNS
DNS -->|新流量: robot-prod-alb-XXXX| LBA
DNS -. "舊流量: 35.x.x.x" .-> LBG
LBA --> K8SA
K8SA --> DBA
LBG --> K8SG
K8SG --> DBG
%% 套用樣式
class ClientNew,ClientOld client
class DNS dns
class LBA,LBG lb
class K8SA,K8SG k8s
class DBA,DBG db
class Note note
新舊架構切換示意圖
遷移流程:漸進式切換(30 天監控期)
%%{init: {
"theme": "base",
"themeVariables": {
"primaryColor": "#e3f2fd",
"primaryTextColor": "#0d47a1",
"primaryBorderColor": "#90caf9",
"lineColor": "#00acc1",
"actorBorder": "#42a5f5",
"actorBkg": "#ffffff",
"noteBkgColor": "#fff3cd",
"noteTextColor": "#4e342e"
}
}}%%
sequenceDiagram
participant Robot as 機器人
participant DNS as GCP Cloud DNS
participant AWS as AWS ALB
participant GCP as GCP LB (備份)
rect rgba(197,225,165,0.35)
Note over Robot,GCP: **Phase 1:單向同步階段(AWS 主 + GCP 備份)**
Robot->>DNS: 查詢 robot-update.example.com
DNS->>Robot: 回傳 AWS ALB IP
Robot->>AWS: 連線到 AWS(主要寫入)
AWS-->>GCP: 單向同步資料
end
rect rgba(255,224,178,0.35)
Note over Robot,GCP: **Phase 2:監控流量衰減**
Note over DNS: 機器人 DNS cache 逐步過期
Note over GCP: GCP 流量從 100% → 80% → 20% → 0.8%
end
rect rgba(179,229,252,0.35)
Note over Robot,GCP: **Phase 3:確認完成(30 天後)**
Note over GCP: GCP 流量趨近於零
Note over AWS,GCP: 關閉 GCP 環境
end
這個解法的價值:
| 步驟 | 方案 A:修改韌體(不可行) | 方案 B:DNS 切換(我們的選擇) |
|---|---|---|
| 1. 準備階段 | 韌體團隊修改 code ⏱️ 2-4 週 ⚠️ 需要跨部門協調 |
設定 AWS 環境 ⏱️ 3 天 ✅ 可控 |
| 2. 測試階段 | 測試新韌體 ⏱️ 1-2 週 ⚠️ 可能有 bug |
設定單向同步 ⏱️ 2 天 ✅ 可控 |
| 3. 執行階段 | 推送韌體更新 ⏱️ 1 天 ✅ 相對簡單 |
改 DNS record ⏱️ 5 分鐘 ✅ 可 rollback |
| 4. 等待階段 | 等待客戶自行升級 ⏱️ 無法預期 ❌ 完全無法控制 |
監控流量切換 ⏱️ 30 天 ✅ 漸進式,安全 |
| 5. 風險管理 | 舊韌體連不上 ⏱️ 持續存在 ❌ 災難性後果 |
客戶不用做任何事 ⏱️ 0 天 ✅ 完全不依賴客戶 |
| 總時間 | 3-7 個月,或是更久 | 30 天 |
| 客戶影響 | ❌ 需要客戶配合升級 | ✅ 完全透明 |
| 可控性 | ❌ 低(依賴客戶行為) | ✅ 高(我們完全控制) |
| Rollback | ❌ 困難(舊韌體已無法連線) | ✅ 簡單(改回 DNS 即可) |
🎯 測試重點 2:雙向非同步複製(Bi-directional Asynchronous Replication)架構驗證
這不是標準的 Active-Passive(因為兩邊都在寫入) 或 Active-Active(通常指對稱流量),而是一個為 IoT 智慧家電場景特製的遷移用過渡架構:
- ✅ 兩邊環境都運作(Active-Active)
- ✅ 雙向資料同步(Bi-directional Asynchronous Replication)
- ⚠️ 但流量不對稱(AWS 接收 99%,GCP 接收 1%)
- ⚠️ AWS 為主要入口(Primary Ingress),GCP 僅處理舊 DNS cache 流量
- 💰由於雙活架構的跨雲出站費用相當高,因此必須儘快完成收斂階段
可以稱為:「Active-Active with Primary Ingress」 或:「不對稱流量的雙活架構」
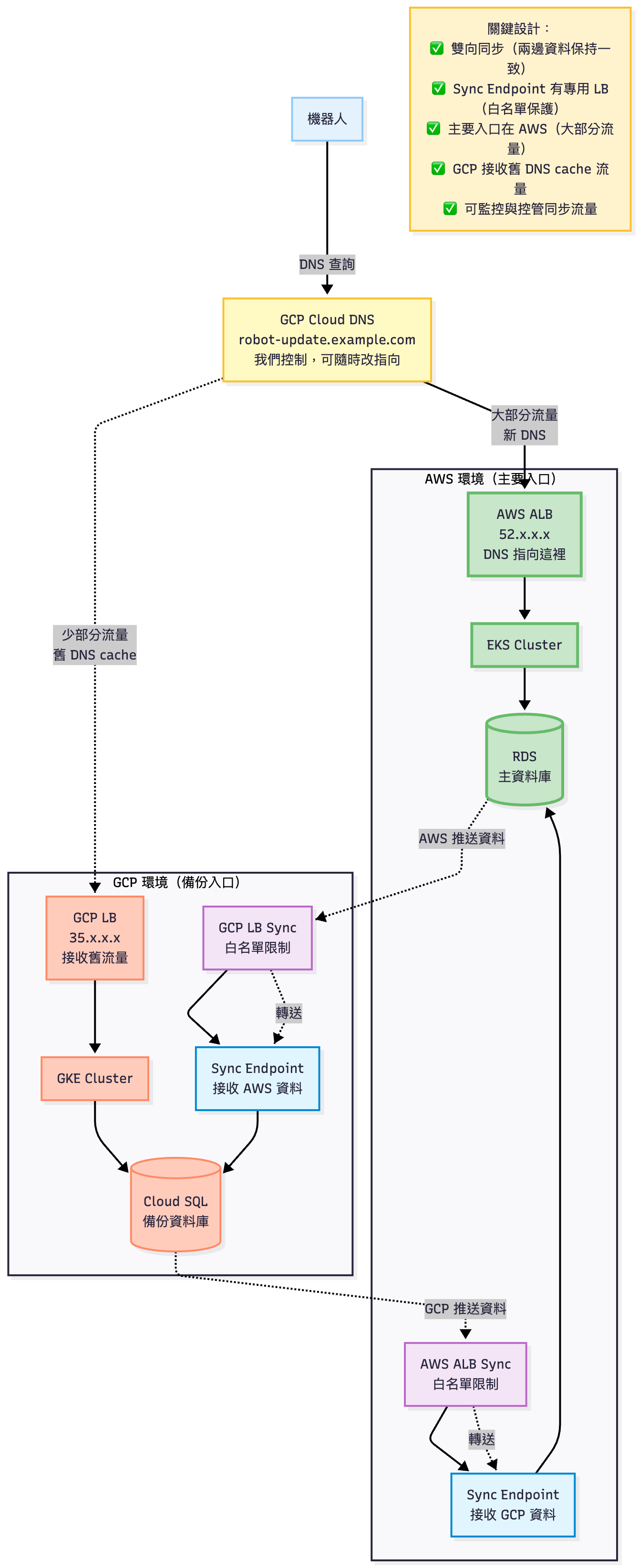
跨雲熱備 (Cross-Cloud Active-Passive) 架構:雙向同步 + DNS 切換 + 自然流量衰減
如果要用精確的術語來形容這個架構,大概就是以下這段話:
Active-Active with Asymmetric Traffic Distribution 使用 Bi-Directional Sync 保持資料一致性,並以 DNS-based Primary Endpoint Migration 配合 Client-side DNS Cache Expiration 實現漸進式切換。
🔹 擬定測試項目,以及遷移風險考慮
開發環境測試項目:
| 測試項目 | 測試方式 | 通過標準 | Dev 結果 |
|---|---|---|---|
| AWS 寫入是否成功 | 對 Endpoint 寫入資料,檢查 RDS | 資料正確寫入 | ✅ 通過 |
| 雙向同步是否正常 | 檢查 AWS ↔ GCP 同步延遲 | < 10 秒延遲 | ✅ 通過 |
| 同步失敗處理 | 模擬網路斷線 | 自動重試機制 | ✅ 通過 |
| 資料一致性 | 比對 AWS RDS vs GCP Cloud SQL | 100% 一致 | ✅ 通過 |
| DNS 切換測試 | 改 DNS record 指向 AWS | 測試用的掃地機器人自動切到 AWS | ✅ 通過 |
| 舊流量處理 | 模擬舊 DNS cache | GCP 仍可接收請求,資料雙向同步 | ✅ 通過 |
但 Production 才會遇到的問題(開發環境測不到):
| 問題類別 | 具體問題 | Dev 環境 | Production 實際 |
|---|---|---|---|
| 規模問題 | 數百萬台機器人同時寫入,同步延遲會拉高嗎? | 幾十台設備 延遲 < 1 秒 |
⚠️ 無法驗證 需上線後觀察 |
| AWS ↔ GCP 網路頻寬夠嗎? | 流量很小 沒問題 |
⚠️ 無法驗證 百萬級流量未知 |
|
| 同步 endpoint 的效能瓶頸在哪? | 測不出來 | ⚠️ 需監控 可能需要擴容 |
|
| 地理分布問題 | 不同地區的設備,網路延遲會影響同步嗎? | 單一地區測試 | ⚠️ 全球分布 延遲差異大 |
| 跨雲雙向同步的 latency 會成為瓶頸嗎? | 測不出來 | ⚠️ 需監控 可接受範圍內 |
|
| 資料一致性問題 | 雙向同步會不會有衝突? | 不會 | ✅ 實際不會 (機器人寫自己的資料) |
| 同一筆資料同時在兩邊被修改怎麼辦? | 測試場景不會發生 | ✅ 不會發生 (不同 robot_id) |
|
| DNS Cache 問題 | 舊 DNS cache 的機器人連 GCP 怎麼辦? | 模擬測試 OK | ✅ 雙向同步確保一致 |
| 新 DNS 的機器人連 AWS 怎麼辦? | 測試 OK | ✅ 主要流量入口 | |
| 監控挑戰 | 怎麼知道所有機器人都切換完成? | 無法測試 | ⚠️ 監控 GCP 流量衰減 |
| GCP 流量什麼時候降到零? | 幾分鐘內切換完畢 | ❌ 實際 30 天 |
Dev 測試結論:
✅ 架構可行
✅ 非同步寫入正常
✅ 不會有資料衝突
Production 實際搬遷過程:
⚠️ 規模問題無法預測(但實際上還好)
⚠️ DNS cache 比預期久很多(30 天 vs 預期幾十分鐘)
✅ 雙向非同步寫入確實保證了資料一致性
✅ 零停機達成
關鍵決策:為什麼選擇「後端雙向非同步寫入」而非「客戶端雙寫」?
| 架構 | 優點 | 缺點 | 我們的選擇 |
|---|---|---|---|
| 客戶端雙寫 (機器人同時寫 AWS + GCP) |
• 兩邊資料即時一致 • 不需要後端同步 |
• 需要改客戶端韌體 • 增加客戶端複雜度 • 如果一邊失敗怎麼辦? • 需要 2-6 個月推韌體 |
❌ 不可行 (無法改客戶端) |
| 後端雙向同步 (AWS ↔ GCP 非同步互抄) |
• 客戶端不用改 • 不依賴韌體更新 • 兩邊資料保持一致 • 客戶端請求不等待同步 |
• 有同步延遲(< 幾秒 ~ 幾十秒,看網路狀態) • 需要監控同步狀態 • 理論上有資料衝突風險 |
✅ 我們的選擇 (不依賴客戶端) |
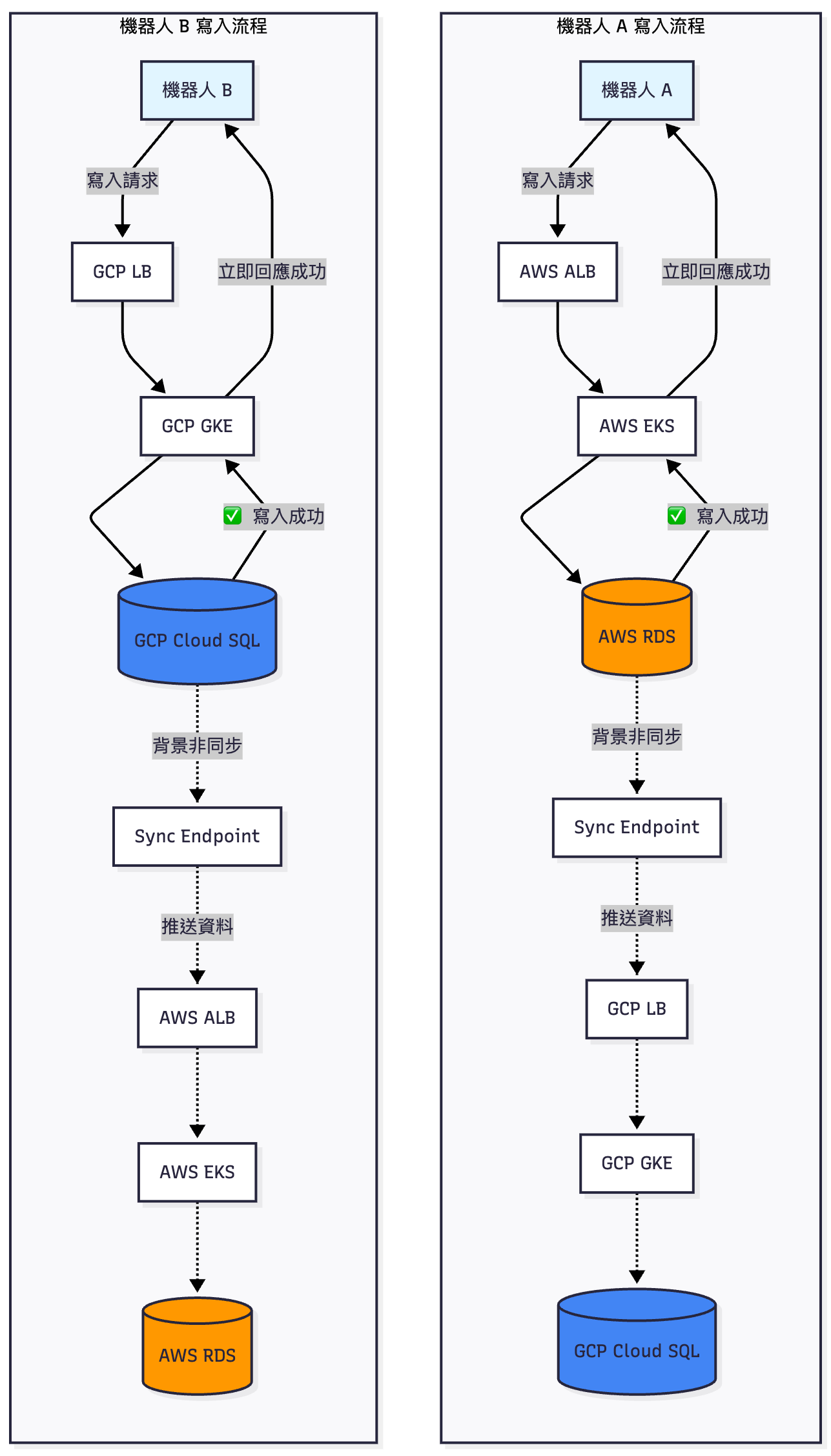
雙向非同步寫入如何運作
關鍵:
✅ 機器人的請求不用等待同步完成
✅ 資料同步是在背景程式非同步執行
✅ 延遲 < 幾秒,但機器人的狀態顯示沒有金融業場景要求的嚴格度,所以可以容許
為什麼不擔心資料衝突?
一般雙向同步的風險:
1 | 場景:多人協作編輯系統 |
我們的場景:IoT 寫入模式
1 | 特點: |
虛構的資料模型範例:
| robot_id | last_update_time | event_type | event_id | location | source_provider |
|---|---|---|---|---|---|
| A | 2025-01-01 10:00 | heartbeat | 23ewfveed | (x₁, y₁) | AWS |
| B | 2025-01-01 10:01 | warning (low battery) | 3gh9sjkqp | (x₂, y₂) | GCP |
| C | 2025-01-01 10:02 | alert (sensor error) | 8kd2vmaa1 | (x₃, y₃) | AWS |
1 | 每台機器人只更新自己的 row |
💡 要注意的是新建立的資料庫必須要向前相容舊資料欄位
如果真的發生衝突怎麼辦?(雖然機率極低)
1 | 策略:Last-Write-Wins (LWW) |
Last-Write-Wins (LWW)
是一種在分散式資料同步中用來解決「兩個節點同時寫入不同值」衝突的規則。
原則是:保留時間戳記最新的那筆寫入,捨棄其他版本。
🔹 結語
本篇文章是以智慧家電掃地機器人來比喻真實的 IoT 跨雲遷移情境。零停機跨雲遷移算是企業常見的需求,然而依照企業內部的實際資源配置、系統歷史以及線上環境需求,會有不同的技術選型考量,本文解法僅供參考。